一个简单免费的ai数字人生成工具Stable Diffusion+Sadtalker
- 专业软件
- 2年前
- 1419
- 更新:2024-03-30 16:24:27
简介
Stable Diffusion是一个能够根据文本描述生成高质量图片的深度学习模型,它使用了一种叫做潜在扩散模型的生成网络架构,可以在普通的GPU上运行。Sadtalker是一个能够根据图片和音频生成视频的开源项目,它使用了一种叫做SadNet的神经网络,可以实现风格化的单图说话人脸动画。本教程将介绍如何使用Stable Diffusion和Sadtalker结合起来,实现从文本到视频的生成。
包里有视频教程需要的直接全部下载即可。

图例


教程
包内包含的文件,点击打开照片数字人文件夹。

启动WEBUI运行.bat程序

打开之后稍等几秒,会弹出一串地址,这个地址复制到浏览器打开即可。

操作界面简单易懂,上传图片上传音频即可,高配置选512,低配256,处理方式选择full即可。静态模式脸部增强勾上点生成就可以了。
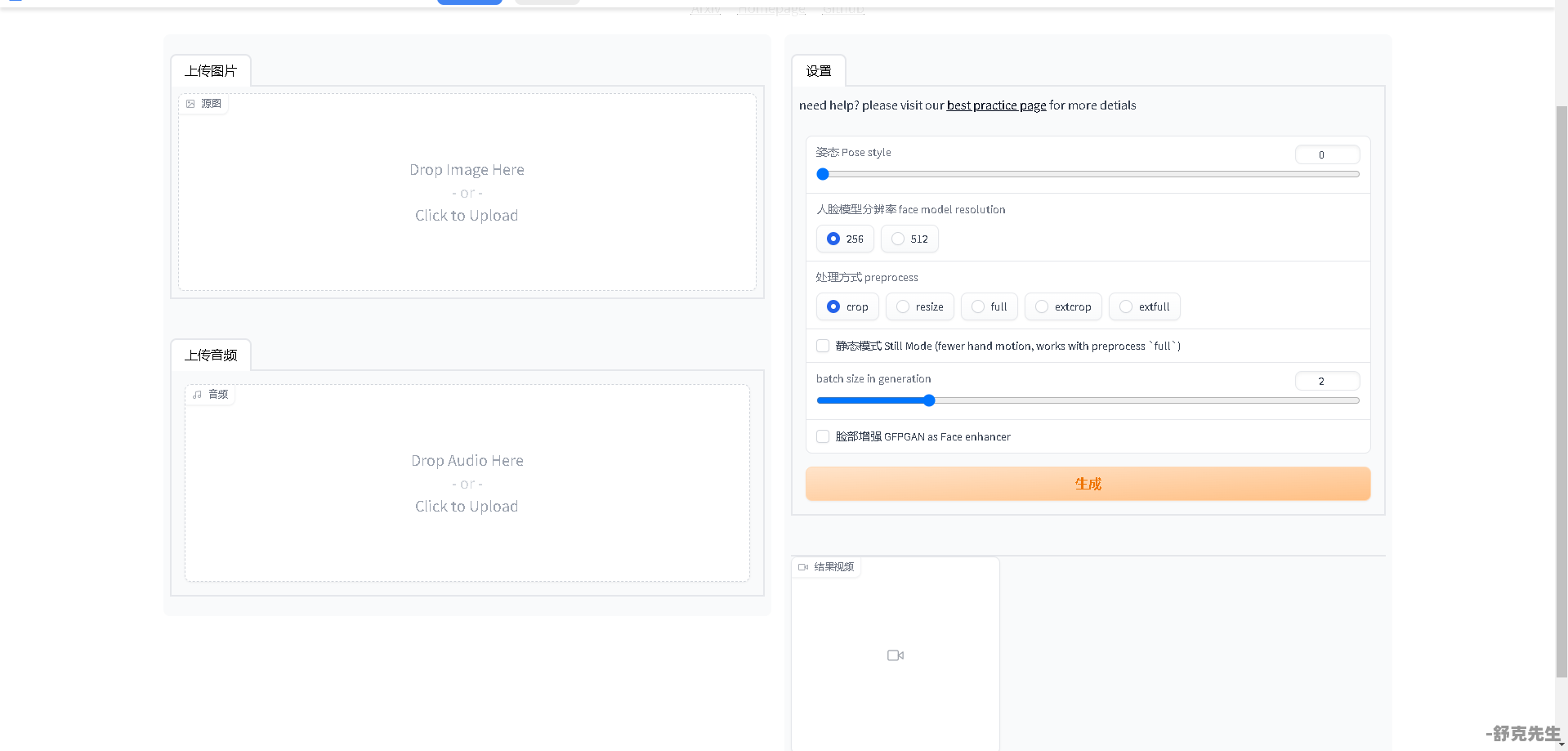
生成之后返回后台会看到进度条在跑直到出现专业就已经算成功了,然后回前台就能看到成品视频了,点开视频下载即可。

配置要求

下载地址
[舒克先生]
链接包含文字转语音工具
链接:https://pan.baidu.com/s/1eqHiXs86B1KyQsK-gTUFkw?pwd=mdlu
[/舒克先生]
本文由 @舒克先生 于2024-03-30原创发布在 舒克先生,未经许可,禁止转载。








有话要说...